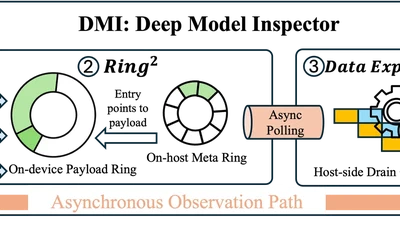
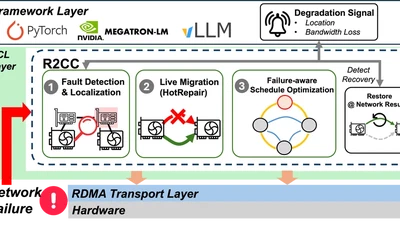
Don't Let a Few Network Failures Slow the Entire AllReduce
OptCC gives an information-theoretic lower bound and a four-stage pipelined AllReduce algorithm for bandwidth-asymmetric failures, staying within 2%–6% of NCCL's fault-free ring …
peiqing-chen