Reliable and Resilient Collective Communication Library for LLM Training and Serving
Abstract
Modern ML training and inference now span tens to tens of thousands of GPUs,
where network faults can waste 10–15% of GPU hours due to slow recovery. We
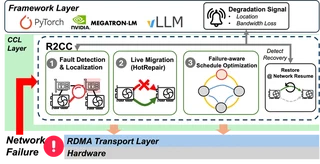
present R2CC, a fault-tolerant communication library that provides lossless,
low-overhead failover by exploiting multi-NIC hardware. R2CC performs rapid
connection migration, bandwidth-aware load redistribution, and resilient
collective algorithms to maintain progress under failures. Evaluated on a
4×8 H100 InfiniBand cluster and large-scale ML simulators modeling up to
1024 GPUs with diverse failure patterns, R2CC is highly robust to inter-node
network failures, incurring less than 1.1% training and 3% inference
overhead under active failure scenarios. Compared to existing fault-tolerant
approaches, R2CC reduces failure-induced overhead by up to 92% for training
and 98% for inference.
Type
Publication
arXiv preprint arXiv:2512.25059